An 8.3 is one of those respectable scores. It gets up at 7 in the morning, put in a solid shift at a white collar job, and comes back home to a moderately happy three-person family. Give a restaurant an 8.3 and rarely will someone pipe up in outrage. At the same time, if you tell me a place is an 8.3 (that’s Cho Dang Gol for me as of February 2025) on your list, I’ll probably nod along in supposed understanding, not caring enough to unpack the surely subtle nuance that you’ve put into said number.
To be quite honest, this isn’t some holier-than-thou post about how my own rating framework is superior. I use Beli for restaurants and I know I don’t have any concrete metric for separating an 8.3 from an 8.1 and an 8.5. I certainly don’t have any reasons that would be consistent across multiple visits to those places, or even of utility to someone that doesn’t value the same vibes, whatever those may be day-of.
Ratings Aren’t Real, They Can’t Hurt You
In fact, I’d say I’m quite a Beli purist. You won’t catch me rating a restaurant weeks after eating there or, god forbid, “saving up” places so I have something to keep my streak going during busy weeks (you know who you are).
The rating implementation leaves a lot to be desired but realistically, this is an issue you’ll find in many “rate-a-place” services. And hey, I don’t use most apps because they cite a paper on generating ratings from pairwise comparisons: me see good UI, me like good UI; everything else is secondary at best.
quite similar to how we judge others, really. I think people are naturally drawn toward those who have “peaks” rather than to generalists and all-rounders. you don’t have to be a genius if you’re incredibly beautiful and I have a plethora of friends that are incredibly smart but have their share of
{'tism, social awkwardness}. this note is turning into quite a tangent but being called an all-rounder is like someone saying you’re nice as a primary descriptor. tough stuff
If you’ve ever played video games, especially RPGs, you’ll be familiar with the illusion that most of these rating systems create.
if you haven’t, good for you. I found playing games to generally be a -EV decision and replacing it with another form of dopamine is >>>
What these systems try to do is create a locally consistent environment. Walk around an in-game city and everything will be essentially at your fingertips. Each key location is conveniently a 2 real-time minute walk from the previous one, giving a sense of scale to each individual action at the expense of the entire world being just too small and convenient. To be clear, this is perfectly correct to the pacing and micro-reality the game tries to sell you. The macro-reality of overall distances and durations is then filled in with some fuzzy extrapolation and suspension of disbelief.
This is the same way most ratings systems work. A score $s_i$ feels like it belongs in the interval $[s_i - \epsilon, s_i + \epsilon]$ (where I’m abusing notation here and $\epsilon$ isn’t really an epsilon-small number) and it is generally easy to conclude that two scores $s_i, s_j$ are associated to different classes of experiences if $|s_j - s_i| > \delta$ for some large enough $\delta$. The issue arises when you try to bridge the $\epsilon$-intuitions into a greater statement about two $\delta$-apart groups.
Data Siens
They call me the Tuco Salamanca of data science. Yum yum blue snacks while I type.
finishing this up a few days later and I have no idea why I wrote that,,, leaving it in for posterity I guess. too much brain rot
any conclusions that follow are drawn from an incredibly small number of samples and the claims I make are first and foremost grounded in personal observation, with the plots simply affirming my belief. this is generally the opposite of how you’d want to approach any causality/correlation problem but I can’t be bothered to rig together bespoke scaffolding to get data from each app that doesn’t have an API. perhaps someday ¯\(ツ)/¯
Now is the point where I put in some plots and force feed you my interpretations!!
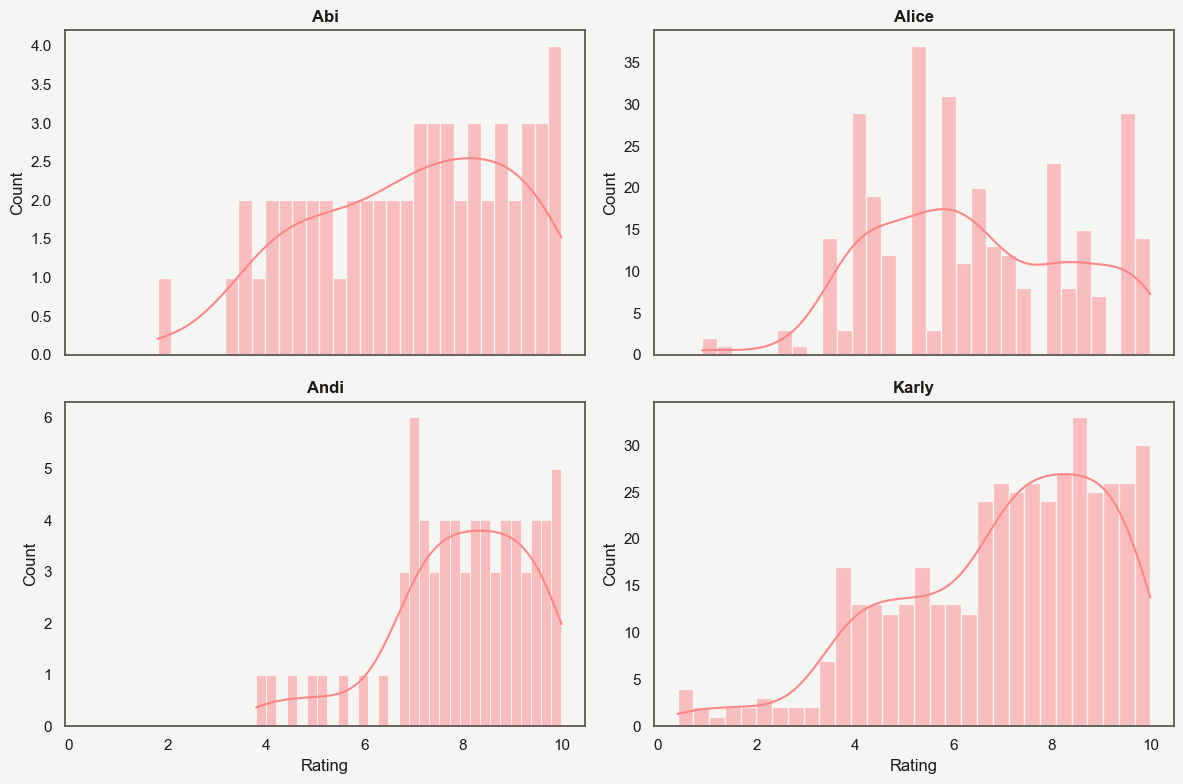
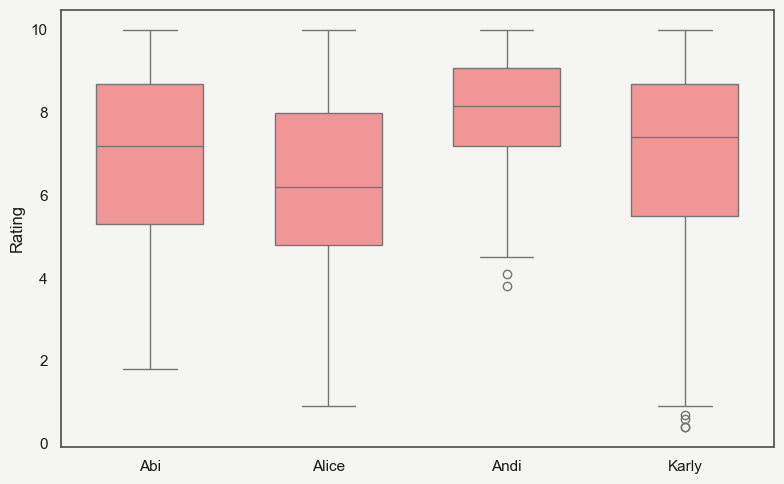
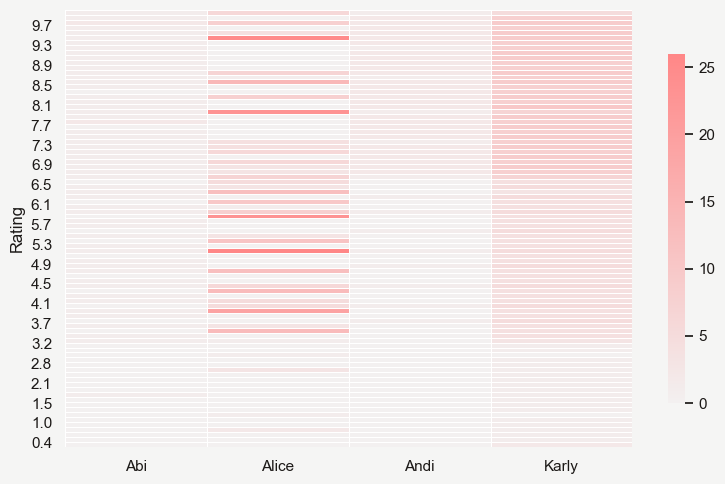
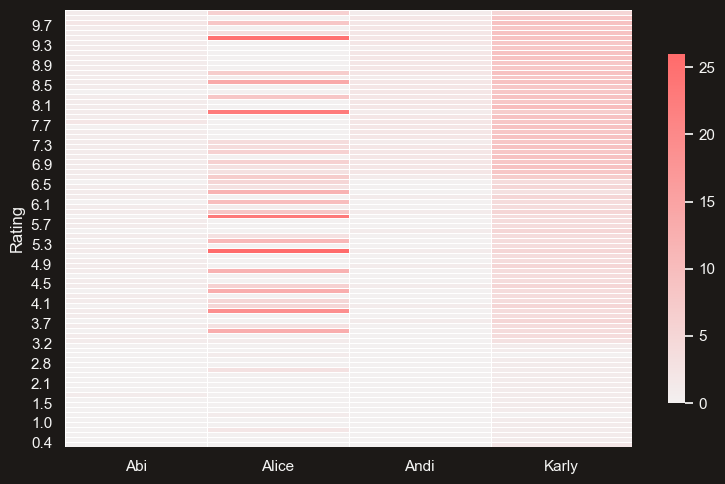
- Andi and I have rated the fewest ($<100$ each) restaurants. Alice comes next, more than doubling us with $358$ places, followed by gourmand Karly, almost doubling again at $608$ places rated as of February 14, 2025
valentine’s ! !
-
Andi and I most clearly epitomize what I think many people’s distributions should look like: almost entirely contained within the $[6.x, 10]$ range. After all, going to a restaurant is generally an active choice, so one expects people to go to places where their prior on the score is high (or the prior is somewhere appropriate the
score-costboundary).- Andi, being more loaded than me, clearly just targets the best places around.
- I try my best, but as a humble blue collar worker
;)I can only manage so much. - Almost all of my low ratings come from places chosen by other people.
-
Karly provides the best data granularity and from her you can see the general Beli paradigm: first filter into
good, fine, badand then interpolate a uniform distribution within each of those groups. -
Alice is a special being. I have no idea how she’s managed to get that shape but if I’m being honest, it feels the most real. Standing a few feet away from my computer and squinting, I can almost imagine a normal distribution.
- I do like that the mean of her distribution is closest to a 5 out of all of my friends
-
There are $101$ possible ratings {$0.1x ; | ; x \in [0, 100]$}, so once you start rating more, it isn’t possible to use Beli as an ordering system.
Interlude: How I Rate on Beli
for Alice, who asked me a month ago and I told her “I’ll think about it and get back to you.” a bit late but here it is
Bad:
- “I wouldn’t come back” and usually “I was forced to come here”
- Anything that just doesn’t taste good
- Anything that isn’t cheap (say, over 50pp) and tastes mediocre
- Anywhere the vibes are off
Fine:
- “I could come back, but I probably wont” (for most places)
- Just fine. Food was edible, I could certainly eat more but at the same time I have no desire to
- There are a lot of places that are quite good, but fall into the “cheap eats” category that get placed into
Fineor into theFine/Goodborder - “I enjoy this myself but I wouldn’t bring someone else here” (unless its a homie)
Good:
- “Good”
- Lower end of good ($[7.x, 8.0]$) is for places that are usually not cheap, have fine vibes/ambiance, but have food that is just alright. “I’d eat it again but I can get a similar experience at many other places”
- Also some things that are hard to rate but I’d go back to (bagel shops, pop-ups, etc.)
- Middle of good $[8.0, 8.7]$ is for places I’d go back to and would take people back to. Solid spots, good for dates, catching up with friends, etc.
- Anything higher is for experiences that I thoroughly enjoyed. Has to be high in food quality, vibes, character, etc. etc.
- There are a few places that may not pass the vibe check as hard but had such amazing food that they get propelled here
Beyond the categories, this is my rating decision tree:
- Gut check, what category does this go in?
- What other places have similar vibes?
- Overall modifier for cuisine, mostly to bump down things I generally dislike (i.e. great Mediterranean food is going to be lower than good Korean food)
- If the place specializes in specific foods I’m not the biggest fan of and I’ve gone with a friend, I use their input to be fair
- Where do I think this should be within the cuisine?
- Immediately gives hard upper/lower bounds to the rating
- I then pick the category and go through the pairwise matchups, with the goal to get the restaurant broadly where the above questions indicate it should be
Five
Five is a good number of distinct categories for humans. Sure, it could be six or four but those numbers are just worse. Go much higher, however, and I don’t think people can appropriately juggle things in their head.
or maybe I’m dumb
If there are 10 boxes to put things into, I think the relationships between box 3 and box 8, etc. get quite fuzzy. Sure, one is better than the other, but more nuanced thoughts tend to exist between closer scores, with those then forming a bridge across larger ranges (see my comment above on $\delta$ and $\epsilon$ similarity)
Five is solid. Was this place good? Great? Mediocre? All things that are easy to answer and all concepts that are easy to compare against each other. In many ways, this is what Beli’s initial categories do: put things into three buckets and then rate within them.
Ratings should exist for utility. Rankings should exist for direct comparison. If the goal is to say “this place is better than that other one”, just expand your range by $1$ for each new restaurant and plop it down where it belongs. If the goal is to decide things like “would I be back” or “would I recommend this place”, five is quite a good number of choices.
TODO
- Figure out what goes on in Alice’s head
- Figure out how Karly has rated so many places
- Implement a good rating system and compare it against Beli
- Write a general scaffold for brute-forcing a pseudo API for apps that don’t have an official one